
Not so long ago I joined HBO as the Site Reliability Engineer. At the moment I work closely with the data team and trust me, we have A LOT of data to deal with. While I do love the challenges and scale of problems I get to experience on daily basis (recent Game of Thrones season, the most popular show in the world is a good example), I absolutely hate my commute and more specifically – Pen Station…
See, when I was working in the Downtown at Mansueto Ventures, the publisher of FastCompany and Inc magazines, I was going to Atlantic Terminal to catch my LIRR train and it was a breeze. There were almost no crowds and service interruptions.
But oh man, Pen Station is a different beast. If you’ve been there I’m sure you know what I’m talking about, especially during morning and afternoon rush hours. Every time you step inside, you get this weird sense of urgency in your gut. People are running, screaming and bumping into each other. A lot of anger is in the air and everyone is united by one common goal – to get out of there as soon as possible!
I did get used to it a little bit over time, but no matter how hard you try to stay calm, the madness just gets you. Especially at those moments when you train arrives at one of those very narrow platforms (most are like that at Penn) and another train right across is about to leave. At that point, the staircase (also VERY narrow, two people wide at best) becomes a real bottleneck, as people try to get out and get in at the same time. Trust me, it’s magical…
Why am I talking about Penn Station and what it has to do with website traffic?
Such an amazing questions, love you guys! 🙂 If you think about it, website traffic is not so different from the real-world traffic. People just want to get to your site and view the content, same way as you want to get in and out of your train station.
Under normal scenario (non-rush hour) everything works fine, only a few people go up and down “the stairs” at the same time. But once you publish some awesome new story that goes viral, everything breaks loose.
If you have just one server, or worse – a shared hosting (you may want to check out my post about different hosting types), then you almost definitely have a very narrow staircase and people will start to queue up.
Unlike Penn Station though, virtual people will not be waiting in the queue for too long. Here are few of the important points related to the website performance (compiled from a range of different sources):
- The average shopper expects your site to load in less than two seconds
-
For every 100 milliseconds of delay, 1% of sales is lost (that was in 2008, I bet now the percent is even higher)
-
Over 75% of consumers left a given shopping site for a competitor’s rather than sit and wait for a slow page to render
-
88% of consumers say they are less likely to return to a site after a bad experience
-
Almost half say that they view the company itself in a negative light after a single bad experience with the company’s website
-
Mobile consumers are 2.5 times as likely to make purchases of $250 or more than those on desktop or laptop computers. Those are especially sensitive to website slowness.
-
Google uses website speed as one of the rankings factors
But performance does not just affect e-commerce sites. A few months ago I had a client who runs a Viral news site. The business idea there was pretty simple – you publish some clickbaity content (local news in that case), drive a lot of traffic from Facebook or other sources and then make money by displaying ads to your visitors. Pretty standard and straightforward.
His site was built on WordPress and it would crash every time it would get a decent amount of traffic. The most interesting part is that the client was not completely aware of the problem. Yes, he saw 504 error pages from time to time but didn’t really know if other visitors were affected as well. In addition to that, the site was running on pretty expensive VPS, which should by definition significantly outperform shared hosting, right?
Well, not necessarily. See, website performance is a tricky subject. A LOT depends on the how the website was built, particular traffic patterns and specific business goals.
The first thing that I usually do when I deal with website performance problems, before changing a single line of code, is gathering current metrics (idle and under load). You can imagine it like going to the doctor, where he takes a blood sample, measuring your heart rate and asks you to pee in the plastic cup.
Same ideas apply to the websites, we just use different tools. For example for external monitoring I usually use Pingdom.
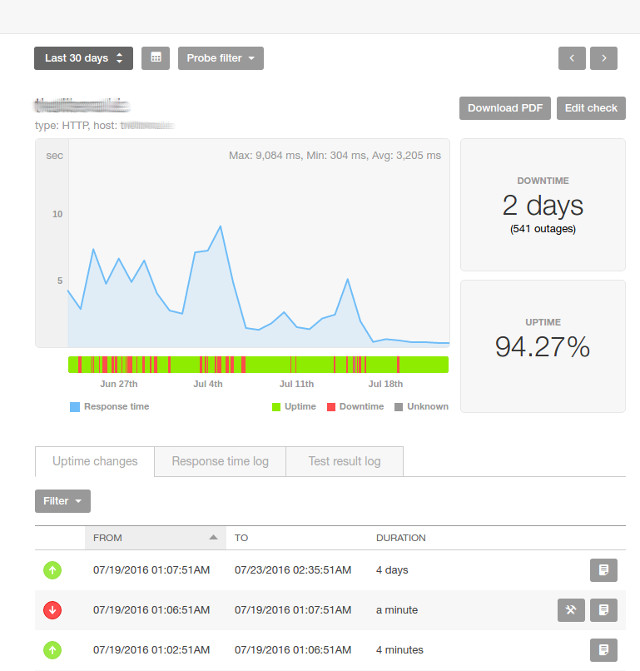
That particular site had 541 outages (or 2 days!) in one month and the owner was completely unaware!
Pingdom basically pings your website every minute from different (configurable) locations in the world and displays all that information on the graph. There is nothing that you need to change on the website to add Pingdom to your site, it’s purely external. Plus it notifies you (via SMS or email or both) if your site goes down or does not respond from particular locations.
The next diagnostic service that I commonly use is Newrelic. It’s not cheap and not as easy to setup as Pingdom. Basically, it’s a piece of software that needs to be installed on the server and normally will not work for sites running on shared hostings (as you don’t have permissions to install anything).
It’s truly powerful if you configure and use it correctly. Newrelic allows you see website internals in real time! (think of it as a full-body MRI scanner for the web)

Some specific WordPress performance optimizations
What did I do for the Viral site I mentioned earlier? Well, the same thing basically. First I hooked it up to Pingdom which allowed me to identify the specific time of the day when the site was typically not available (down). Then I installed Newrelic on the client’s VPS and observed the site under load.
Those two steps gave me enough information to start changing stuff. In that particular case, I had to clean up a lot of the plugins and redo the whole theme. One of the major problems was related to ads, the main revenue generator for that website. Here is why.
An old WordPress theme was not mobile optimized (not responsive), so the client purchased a plugin called WPTouch Pro which made his theme look good on mobile devices. The problem was hidden in the details (as usual). In order for this plugin to work properly, every website request had to reach WordPress (PHP + database), check if that’s mobile device or not and then return modified HTML and CSS.
Another major bottleneck was related to Ad Rotator plugin. It worked in the combination with WPTouch and suffered from the same issue – the plugin was doing some logic on the backend to determine which ads to show and where, which meant we had to accept and pass the whole request to WordPress.
When we redid the theme, we dropped both WPTouch and AdRotator and moved ads logic to the frontend (rendered ads with JavaScript), then we added one of the free caching plugins (I think it was W3 Total Cache) that helped us to save whole WordPress posts and pages as HTML files.
Then I installed the community version of Nginx, a very lightweight and lightning fast web server that I highly recommend, and configured it so that for every incoming request we would first check if there was ready to use HTML file (cache) already and ONLY when it wasn’t there I would let the request go to WordPress backend to generate and serve the page (then save in cache for next requests).
By the way, the same caching technique works perfectly for the majority of content heavy websites with lots of pages that almost never change after initial publishing.
After those few major changes, the client’s website was alive again and was able to survive most of the traffic spikes. Why did I say most? Because it would still go down once or twice a week (instead of multiple times a day previously) during massive visitors influx (thousands of requests per second).
Not going to lie, it was a pretty interesting problem which took me quite a bit of time to understand and fix. Turned out it was related to social counters and Ultimate Social Deux plugin.
When we loaded the page from cache (super fast) it then did another client-side (AJAX) request to the server to get the current share counters for the post. Those requests had to go directly to WordPress and then database, get the data and return a response.
Now you can easily imagine what happens when thousands of people load same Viral story at the same time – all of those requests had to fetch share counters from the database… Even though the response time for each request was fast, one server just couldn’t handle the load. There are multiple solutions to this problem, we decided to go with the simples one and fetch counters only periodically (during main cache refresh). That solved the last major performance bottleneck.
The client was so happy with our work in the end that he even recorded a testimonial!
Super cool right? 🙂 I know. It’s always nice to get some appreciation. Thanks, Leo!
Avoid premature optimizations!
Now, if you are dealing with only a handful of requests a day, you don’t need to start removing your plugins after reading this post! Most likely your website will be just fine for a while. Only when you start getting some traction and the site starts to slow down or even die periodically, that’s when you need to start considering deep optimizations. Focus on the business side and get that precious traffic first!
Here we looked at one example of dealing with traffic volume. Sure, we can cache full HTML pages and survive substantial spikes that way, but unfortunately, this strategy also has some limits. More specifically, if we are dealing with very dynamic content (real-time stuff) or an e-commerce store, which needs to reflect up-to-date stock quantities after each order and show relevant products and recommendations, or just general personalized content (social network style), we can’t just blindly cache the whole thing. That’s when it becomes tricky…
For those scenarios, it might be perfectly reasonable to start scaling out (add more servers). Let’s get back to our Penn Station example, as it’s perfect for showing traffic handling strategies 🙂
See what is going on there? There are multiple lines and even stairs in the middle! You can think of each line as a server. The more lines we have, the more traffic we can handle (unless they have some shared bottleneck like the database…).
The other added benefit of having multiple servers is not having a single point of failure. Thanks to the beauty of cloud computing, I’m fortunate enough to work with dynamic systems that involve not just one or ten, but thousands of virtual servers and trust me, they do fail a lot.
Some servers are going through scheduled maintenance, some die for unexplained reasons, some are terminated (retired) by hosting provider. The point is, you need to prepare for disaster and having multiple servers is the first step in the right direction.
I have another Penn Station picture that I took yesterday to illustrate my point:

As you can see, even though one line is currently shut down and undergoing repairs (for days!), people can still go up and down. The trick here is to schedule your maintenance at the right time (preferably off-peak hours). I hope one of the Penn Station officials will read this post and will make things better for all of us (if you don’t forget to share it of course!)…
Get the idea? One server – whole site fails. Mulitple servers – no single point of failure. Great, great.
Let me repeat one more time, if you are just starting out with your project, don’t stress out about the concepts of single point of failures and stuff. I just wanted to show you what’s possible.
It’s VERY easy to get into the technical nitty-gritty and waste a lot of time making the system more scalable and stable only to realize that your business idea sucks. It may give you a false sense of important activity, but in reality what you do is premature optimization. Don’t do it, save yourself, run away.
I meant to say feel free to ping me if your site is suffering from performance problems and don’t forget to subscribe to my list. I periodically release useful stuff ranging from technical topics to marketing and investing. Let me put it this way, if you want to stay on top of your game and if you are reading these lines at the end of my 2K words post, you absolutley HAVE to join my list! Come on, you know it. ))
Leave a Reply